
Desaprendizaje automático multiobjetivo alineado con referencia
RAUL: un marco multiobjetivo que elimina datos de entrenamiento sin perder precisión. Optimiza olvido y retención con alineación de referencia.
RAUL: un marco multiobjetivo que elimina datos de entrenamiento sin perder precisión. Optimiza olvido y retención con alineación de referencia.

Descubre cómo las simetrías en el espacio de pesos facilitan la estimación de la curvatura en redes neuronales, mejorando la optimización y reduciendo costos computacionales.
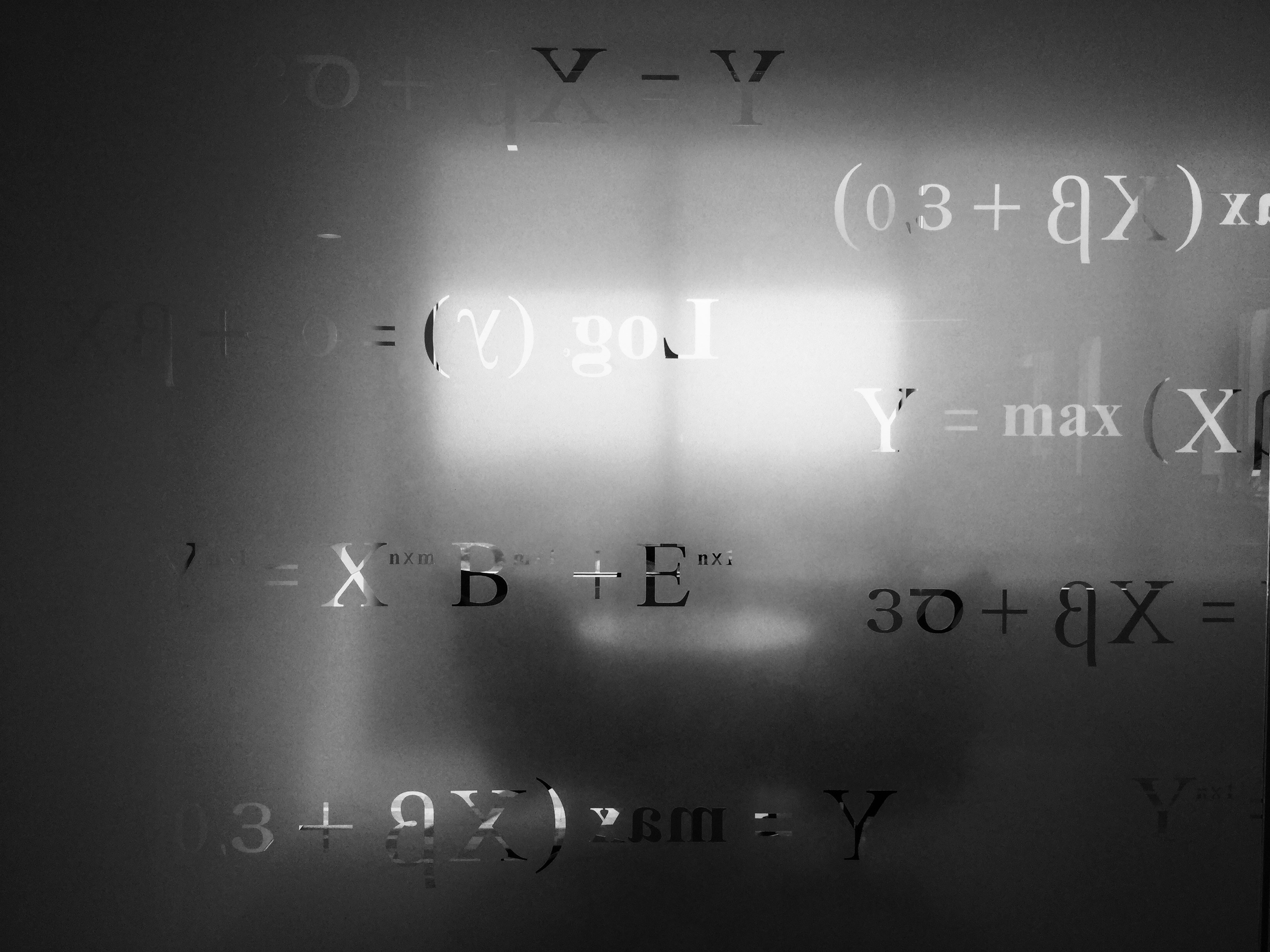
Descubre cómo las divergencias de Bregman distribuyen el error de aproximación espectral en optimizadores Kronecker y la propuesta de un optimizador adaptativo.
ATOM: marco multiagente que coordina agentes en un árbol para optimizar moléculas multiobjetivo. Mejora Pareto en diseño de fármacos. ¡Descúbrelo!

Descubre cómo la Optimización Bayesiana invariante a permutaciones, basada en transporte óptimo, reduce a la mitad el tiempo de cómputo y mejora el diseño de parques eólicos marinos.

Descubre CityTrajBench, el benchmark unificado para generar trayectorias vehiculares urbanas. Compara modelos como DiffTraj, GANs y flujos. Resultados multiobjetivo clave.

MASER: un framework que selecciona la mejor modalidad para responder preguntas espaciales 3D con alta precisión. Basado en Open3D-VQA.

AdaCodec reduce tokens visuales en video MLLMs hasta 1/7, mejorando benchmarks y reduciendo tiempo de primera respuesta de 9.26s a 1.62s.

Aprende cómo las correlaciones espurias en VLM crean un espejismo de seguridad y cómo el desaprendizaje reduce ataques y rechazos innecesarios.

Descubre el nuevo benchmark InPhyRe revela: modelos multimodales fallan en razonamiento físico inductivo, cuestionando su fiabilidad en aplicaciones críticas.
Explora cómo los LLMs combinados con simulaciones físicas facilitan la síntesis de materiales inorgánicos. Caso práctico: sistema niobio-oxígeno.

Descubre cómo las Políticas de Difusión Parametrizadas (PDP) transforman el ruido en control, adaptando comportamientos robóticos sin reentrenar el modelo. Resu

Descubre cómo las políticas de difusión parametrizadas permiten adaptar comportamientos robóticos sin reentrenar, mejorando la síntesis de nuevas conductas.

Descubre cómo VESTA equipa agentes de IA con herramientas visuales dinámicas para explorar y refinar modelos estadísticos con mayor precisión.

Descubre TAPS, que acelera la decodificación especulativa hasta 7.9x con selección inteligente de árboles de prefijos. Mejora el rendimiento sin pérdidas.
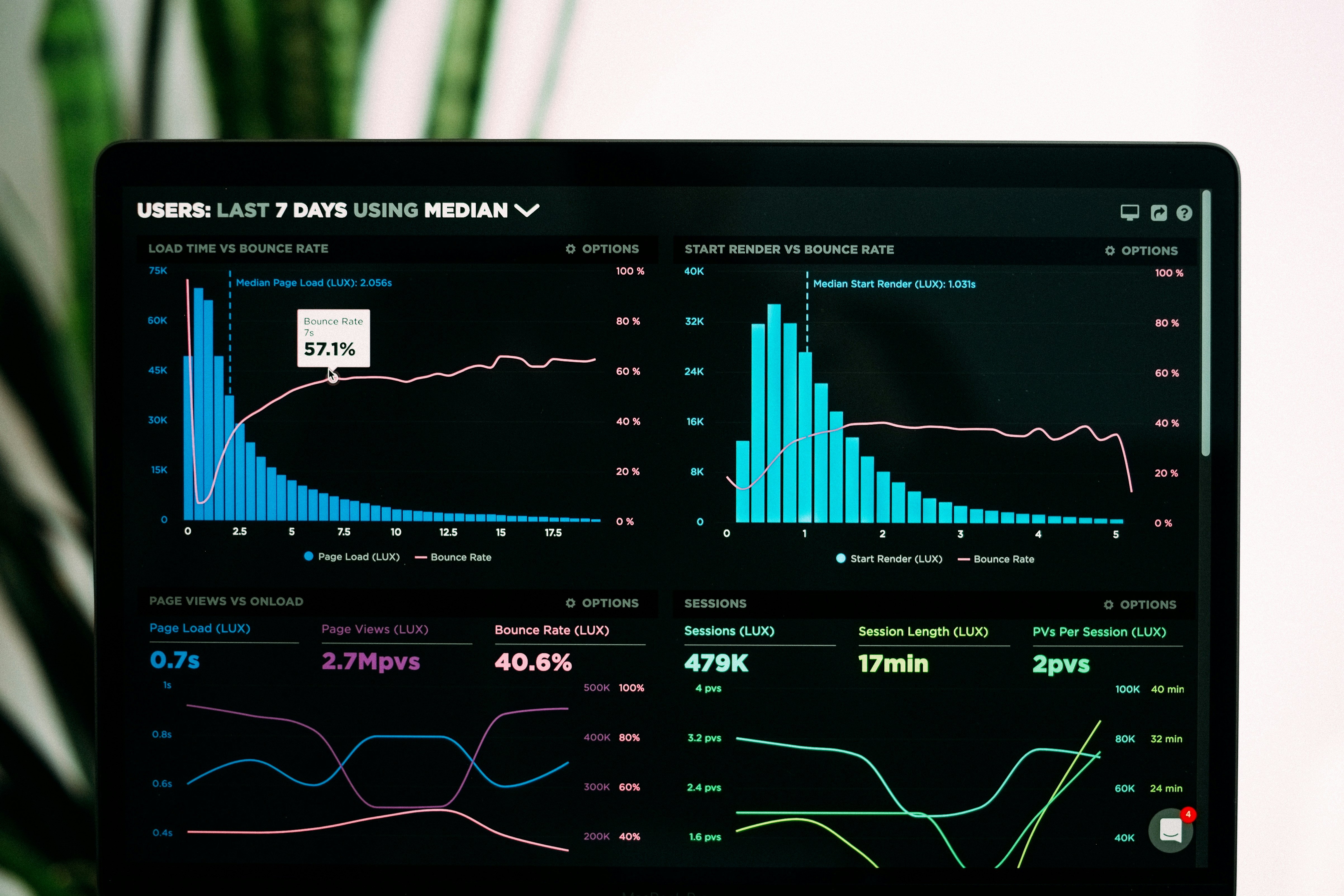
Aumenta la precisión en predicción de consumo energético en un 5% con EnergyMamba, modelo que cuantifica incertidumbre mediante grafos y estados selectivos.

Descubre cómo CoEvo-AHD usa LLMs para co-evolucionar heurísticas en problemas de optimización acoplada como TTP y TPP, mejorando soluciones de forma automática.

Aprende cómo LFTutor, un tutor con IA, enseña a detectar falacias lógicas usando preguntas socráticas para combatir la desinformación. ¡Mejora tu pensamiento!

Descubre MindClaw, un marco de IA que permite a robots razonar sobre el estado mental y actuar solo cuando es necesario, mejorando asistencia robótica precisa.

Descubre CAREAgent, el agente clínico que combina razonamiento estructurado y herramientas integradas para generar órdenes clínicas precisas. Mejora el F1 un 5%